Published: Feb 8, 2021 by Dev-hwon
Anomaly Detection with Generative Adversarial Networks for Multivariate Time Series Dan Li, Dacheng Chen, Jonathan Goh, and See-Kiong Ng, 2018 ICANN conf.
논문을 읽고 고려대학교 산업경영공학부 DSBA 연구실 김혜연 선배님의 스터디 발표 자료를 참고하였습니다.
Anomaly Detection with Generative Adversarial Networks for Multivariate Time Series
- Conventional detection techniques들은 점점 더 복잡해지고 다이나믹해지는 CPS(Cyber-Physical Systems)들의 특성을 다루기 어렵다.
- Networked sensor와 actuators는 많은 양의 데이터스트림을 생성한다.
머신러닝을 사용해도 여전히 해결해야 할 문제
1) 대부분의 지도학습은 충분한 정상데이터와 레이블된 anomaly classes 데이터가 필요하다. 하지만 anomaly 데이터는 적다.
2) 대부분의 기존 비지도 방법은 선형 투영 및 변환을 통해 구축되지만 복잡한 CPS의 다변량 시계열의 숨겨진 내재적 상관관계에는 종종 비선형성이 존재한다.
3) 대부분의 기술은 현재 상태와 예상되는 정상 범위간의 간단한 비교 사용한다. 제어 범위가 충분히 유연하지 않고 간접공격을 효과적으로 식별하지 못한다.
Related works
-
anomaly detection은 크게 세가지로 구분
1) Statistical Process Control(SPC) techniques
2) Supervised machine learning methods
3) Unsupervised machine learning methods
SPC
- 단일 변수의 mean shift를 detect하는 Shewhart control charts와 CUSUM control charts, 단일 변수의 variance change를 이용한 EWMV control charts
- 다양한 시퀀스 간의 상관관계를 이용하지 못한다는 단점
- 다변량을 위한 Multivariate Cumulative Sum(MCUSUM), Multivariate Exponentially Weighted Moving ASverage(MEWMA)
- 독립과 동일한 분포 필요, 복잡도가 높고 데이터스트림이 많은 최신 CPS에는 실용적이지 않다.
Supervised machine learning
- normal과 anomalous classes 분류 예측 모델 생성
- 많은 지도학습 기법 사용 가능(Multivariate Regression models, Bayes Classifier, Neural Networks, Fisher Discriminant Analysis, etc)
- 레이블이 지정된 초기 training dataset의 가용성에 의존
Unsupervised machine learning
- 간단하고 많은 수의 데이터 처리 가능으로 널리 사용
- highly correlated data에만 효과적, 다변량 가우시안 분포를 따라야 한다.
GAN
- 잠재적으로 상호작용하는 시계열 데이터의 여러 스트림 처리
- multi sequences는 i.i.d로 다뤄지고 uniform GAN에 사용
- 복잡한 시스템의 동일하거나 다른 프로세스에 관련된 sensors 및 actuators간의 잠재적 상호작용을 고려할 때 IoT 및 CPS 설정에 적합하지 않다.
GAN with LSTM-RNN
- GAN에 대해서는 워낙 유명하니 자세하게 다루지는 않겠다.
- 간단하게 GAN에는 generator와 discriminator 두개의 모델이 존재한다.
- 두 모델이 적대적(Adversarial)으로 경쟁시키며 발전시킨다.(two-player minimax game)
- generator는 실제와 비슷하게 samples을 생성하여 discriminator를 속이고
- discriminator는 generator가 만든 가짜를 찾아낸다.
구조
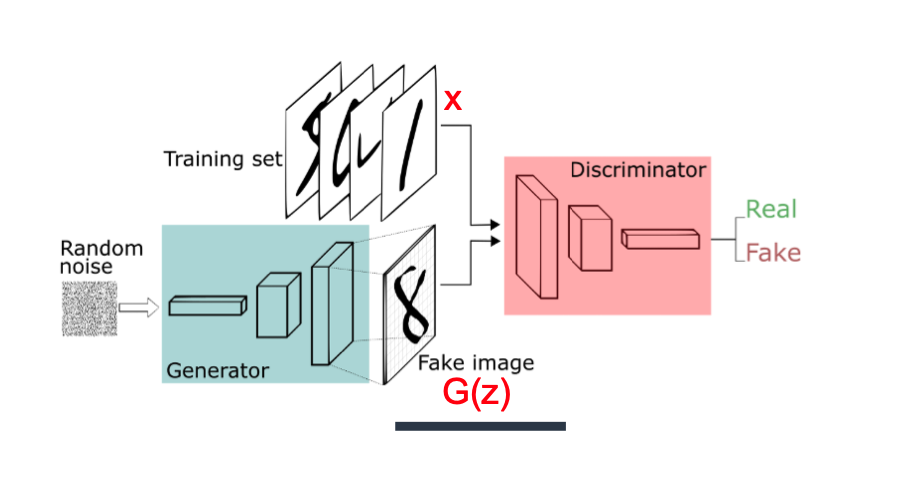
Discriminator loss
\[\begin{aligned} D_{loss}=\frac{1}{m}\sum^m_{i=1}[\text{log}D_{rnn}(x_i)+\text{log}(1-D_{rnn}(G_{rnn}(z_i)))] \\ \Leftrightarrow min\frac{1}{m}\sum^m_{i=1}[-\text{log}D_{rnn}(x_i)-\text{log}(1-D_{rnn}(G_{rnn}(z_i)))] \end{aligned}\]Genertor loss
\[\begin{aligned} G_{loss}=\sum^m_{i=1}[\text{log}(1-D_{rnn}(G_{rnn}(z_i)))] \\ \Leftrightarrow min\sum^m_{i=1}\text{log}[-D_{rnn}(G_{rnn}(z_i))] \end{aligned}\]Propose a novel Unsupervised GAN-based Anomaly Detection(GAN-AD)
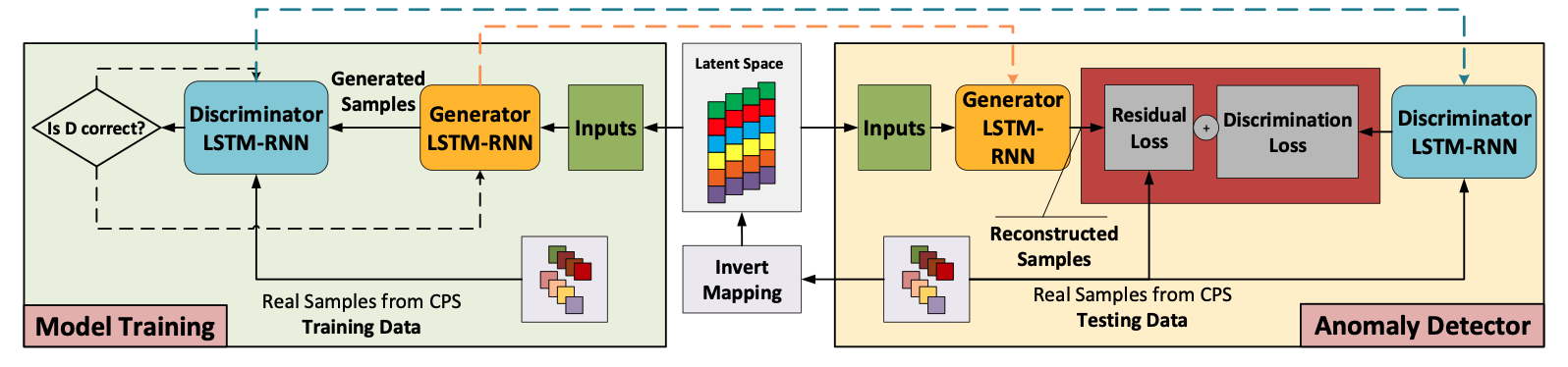
- latent vector: normal data feature들을 가지고 있는 vector
- Genertor: fake data이지만, abnomarl한 데이터 말고 normal한 데이터를 생성해 내려고 normal data로만 학습 진행
Model training
1) 시계열 데이터를 다루기 위해 generator(G)와 discriminator(D) 둘 다 LSTM-RNN으로 구성
2) Normal data로만 G와 D 학습
- G가 특정 latent space로부터 fake data를 생성하고 D가 fake를 구별
- D의 output을 기반으로 D와 G 파라미터 업데이트
- D는 정확한 레이블 구별, G는 D를 속이게 학습
- 충분한 iteration후 G는 training sequences의 숨겨진 분포를 찾아내고 실제 샘플과 유사하게 생성 가능 3) 학습 후 G와 D의 parameter는 고정
Anomaly Detector
1) Invert Mapping
- real-time testing samples를 latent space로 invert mapping하여 재구축된 샘플 생성
- Invert Mapp이란 최대한 x와 비슷한 이미지를 만드는 최적의 z값
2) Residual loss
- real-time testing samples과 재구축된 샘플과 잔차를 계산
3) Discrimination loss
- D에 real-time testing samples를 넣어 discrimination loss \(D_{rnn}(X^{tes}_t)\) 계산
4) 최종 loss = Anomaly score
\[\begin{aligned} S_t^{tes}&=\lambda Res(X^{tes}_t)+(1-\lambda)D_{rnn}(X^{tes}_t) \\ &=\lambda \sum^n_{i=1}\left | x_t^{tes,i}-G_{rnn}(Z_t^{k,i}) \right | + (1-\lambda)D_{rnn}(X^{tes}_t) \end{aligned}\]5) Anomaly score > \(\tau\)이면 anomaly detect
\[A^{tes,i}_t=\left\{\begin{matrix} 0&if \; H(S(x^{tes,i}_t),1)>\tau\\ 1& else \end{matrix}\right.\]algorithm pseudo

평가 지표
- GAN이 training data를 학습한 분포를 평가하기 위해 Maximum Mean Discrepancy(MMD)를 사용
- MMD는 moment matching network의 학습 목적식 중 하나
- 두 분포의 moment를 통해 거리를 수치화
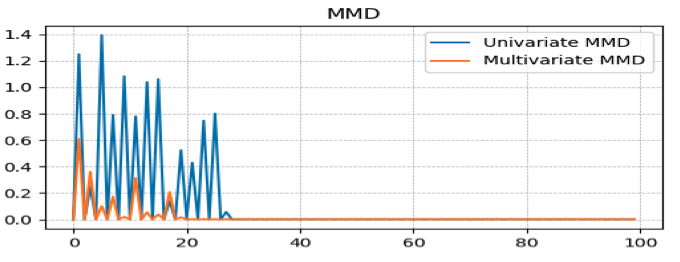
초기에 다변량이 더 작고 수렴도 빠르다.
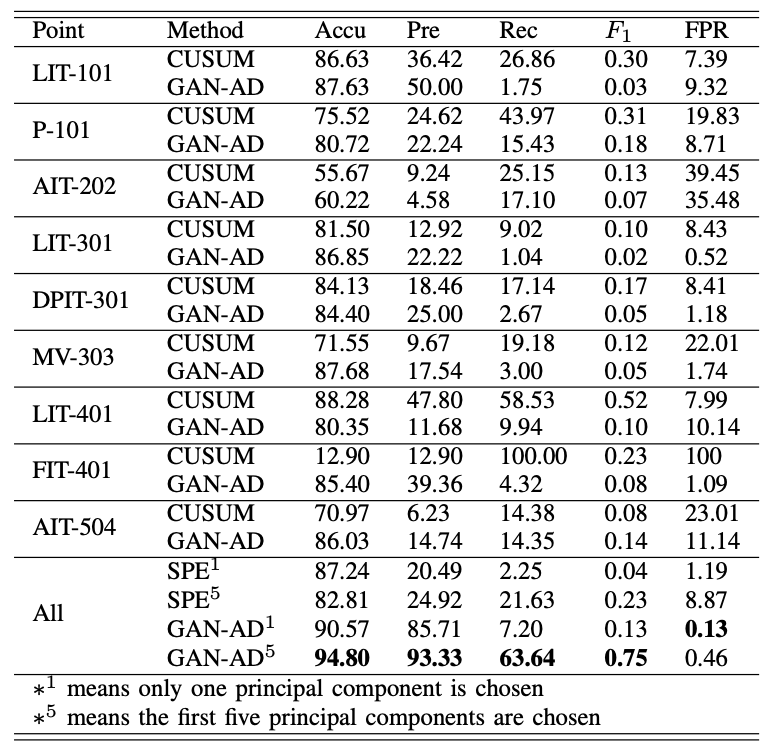
- GAN_AD 평가 지표
- Accuracy(Accu), Precision(Pre), Recall(Rec), \(F_1\) score, False Positive Rate(FPR)
- 단변량은 CUSUM 기법과 비교
- 다변량은 GAN-AD와 PCA 기반 비지도 방법(SPE) 비교
- 결과
기여점
- 복잡한 multi-process systems에서도 detection 가능
- Image 도메인에서 time series 분야로(by using LSTM-RNN)
- GAN을 학습시킬 때 Normal data가 균등하게 사용됨
- Discrimation loss 와 residual loss 동시에 고려 (outperform)
- 기존 Anomaly detection(CUSUM, EWMA, Shewhart)와는 다르게 역동적이고 복잡한 non-linear한 데이터에서도 성능이 좋음


