Published: Jan 10, 2020 by Dev-hwon
beautifulsoup
- beautifulsoup 모듈 설치하기
$ pip install beautifulsoup4
- beautifulsoup 모듈 사용하기
from bs4 import Beautifulsoup
- HTML 문자열 파싱
(1) html 파일 열기
with open("example.html") as f:
soup = BeautifulSoup(f, 'html.parser')
(2) urllib를 통해서 웹에 있는 소스 가져오기
import urllib.request
import urllib.parse
with urllib.request.urlopen(web_url) as response:
html = response.read()
soup = BeautifulSoup(html, 'html.parser')
(3) requests를 통해서 웹에 있는 소스 가져오기
import requests
req = request.get(web_url)
- 예시 HTML
html='''
<html>
<head>
<title>Hello BeautifulSoup</title>
</head>
<body>
<div id='upper' class='test'>
<h3 title='Content Title'>Content Title</h3>
<p>Test Content</p>
</div>
<div id='lower' class='test'>
<p>Test 1</p>
<p>Test 2</p>
<p>Test 3</p>
</div>
</body>
<html>'''
- find 함수
- 특정 html tag를 검색
- 검색 조건을 명시하여 찾고자 하는 tag 검색
- 해당 조건에 맞는 하나의 태그(첫 번째 태그)를 가져온다.
soup = BeautifulSoup(html)
print(soup.find('h3'))
print(soup.find('p'))
print(soup.find('div'))
print(soup.find('div', custom='2nd'))
print(soup.find('div', class_='test')) # class는 키워드이기 때문에 뒤에 _
# 여러 태그를 줄 때
attrs = {'id': 'upper', 'class': 'test'}
print(soup.find('div', attrs=attrs))
# 출력 결과
<h3 title="Content Title">Content Title</h3>
<p>Test Content</p> # 가장 첫 번째 태그만 찾는다.
<div class="test" custom="1st" id="upper">
<h3 title="Content Title">Content Title</h3>
<p>Test Content</p>
</div>
<div class="test" custom="2nd" id="lower">
<p>Test 1</p>
<p>Test 2</p>
<p>Test 3</p>
</div>
<div class="test" custom="1st" id="upper">
<h3 title="Content Title">Content Title</h3>
<p>Test Content</p>
</div>
<div class="test" custom="1st" id="upper">
<h3 title="Content Title">Content Title</h3>
<p>Test Content</p>
</div>
- find_all 함수
- 조건에 맞는 모든 tag를 리스트로 반환
soup.find_all('div')
# 출력 결과
[<div class="test" custom="1st" id="upper">
<h3 title="Content Title">Content Title</h3>
<p>Test Content</p>
</div>, <div class="test" custom="2nd" id="lower">
<p>Test 1</p>
<p>Test 2</p>
<p>Test 3</p>
</div>]
- get_text 함수
- tag안의 value를 추출
- 부모 tag의 경우, 모든 자식 tag의 value를 추출
tag = soup.find('h3') print(tag) print(tag.get_text()) tag = soup.find('div') print(tag) print(tag.get_text())
# 출력 결과
<h3 title="Content Title">Content Title</h3>
Content Title
<div class="test" custom="1st" id="upper">
<h3 title="Content Title">Content Title</h3>
<p>Test Content</p>
</div>
Content Title
Test Content
- attribute 값 추출하기
- 경우에 따라 추출하고자 하는 값이 attribute에도 존재함
- 이 경우에는 검색한 tag에 attribute 이름을 []연산을 통해 추출가능
tag = soup.find('h3')
print(tag)
print(tag['title'])
# 출력 결과
<h3 title="Content Title">Content Title</h3>
'Content Title'
CSS를 이용하여 tag 찾기
- select, select_one 함수 사용
- css selector 사용법
- 태그명 찾기 tag
soup.select('div')- 자손 태그 찾기 - 자손 관계 (tag tag)
soup.select('div p')- 자식 태그 찾기 - 자식 관계 (tag > tag)
soup.select('div > p')- 아이디 찾기 #id
soup.select('#lower')- 클래스 찾기 .class
soup.select('.test') # or div.test-
속성값 찾기 [name=’test’]
soup.select('div[class="test"]')- 속성값 prefix 찾기 [name ^=’test’]
soup.select('h3[title^="C"]')`- 속성값 suffix 찾기 [name $=’test’]
soup.select('h3[title$="e"]')- 속성값 substring 찾기 [name *=’test’]
soup.select('h3[title*="tle"]') -
n번째 자식 tag 찾기 :nth-child(n)
soup.select('div.test:nth-child(1)')
추가 내용
HTTP 상태 코드
- 1xx (정보): 요청을 받았으며 프로세스를 계속한다.
- 2xx (성공): 요청을 성공적으로 받았으며 인식했고 수용하였다.
- 3xx (리다이렉션): 요청 완료를 위해 추가 작업 조치가 필요하다.
- 4xx (클라이언트 오류): 요청의 문법이 잘못되었거나 요청을 처리할 수 없다.
- 5xx (서버 오류): 서버가 명백히 유효한 요청에 대해 충족을 실패했다.
처음 요청으로 받을 수 없는 정보 얻기
- 처음 요청으로 받을 수 없고 추가 요청으로 가져 오는 자료 크롤링 방법
- 예로 다음 기사 댓글 수 가져오기
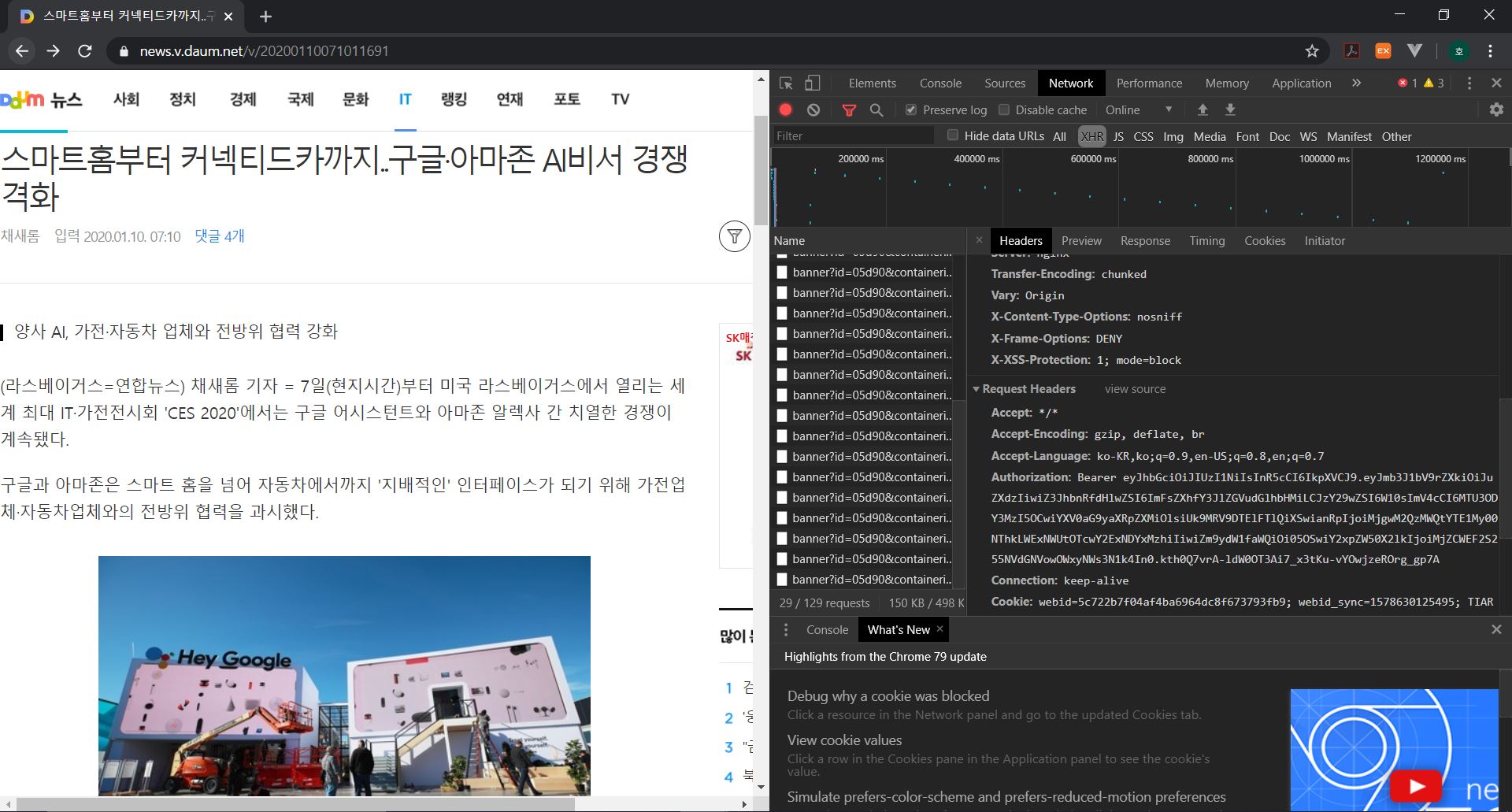
‘개발자 도구-Network’에서 댓글 수를 가져오는 url 이용
url = 'https://comment.daum.net/apis/v1/posts/@20200110071011691'
resp = requests.get(url)
print(resp)
<Response [401]>
읽어올 수 없다.
위 이미지 처럼 headers를 가져온다.
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'ko-KR,ko;q=0.9,en-US;q=0.8,en;q=0.7',
'Authorization': 'Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb3J1bV9rZXkiOiJuZXdzIiwiZ3JhbnRfdHlwZSI6ImFsZXhfY3JlZGVudGlhbHMiLCJzY29wZSI6W10sImV4cCI6MTU3ODY3MzI5OCwiYXV0aG9yaXRpZXMiOlsiUk9MRV9DTElFTlQiXSwianRpIjoiMjgwM2QzMWQtYTE1My00NThkLWExNWUtOTcwY2ExNDYxMzhiIiwiZm9ydW1faWQiOi05OSwiY2xpZW50X2lkIjoiMjZCWEF2S255NVdGNVowOWxyNWs3N1k4In0.kth0Q7vrA-ldW0OT3Ai7_x3tKu-vYOwjzeROrg_gp7A',
'Connection': 'keep-alive',
'Cookie': 'webid=5c722b7f04af4ba6964dc8f673793fb9; webid_sync=1578630125495; TIARA=4tyNbxA-QjdUlV9L3TldRm8NMDD.X.RlTkrwLqNsbAUIVLE3mZPIf-VyC5f653WAX74XToIdjgR8df32f7frvqNIqtju9DsP',
'Host': 'comment.daum.net',
'Origin': 'https://news.v.daum.net',
'Referer': 'https://news.v.daum.net/v/20200110071011691',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36'
}
resp = requests.get(url, headers=headers)
print(resp)
<Response [200]>
Json 파일 확인
resp.json()
{'childCount': 0,
'commentCount': 4,
'createdAt': '2020-01-10T07:11:02+0900',
'flags': 0,
'forumId': -99,
'icon': 'https://img1.daumcdn.net/thumb/S1200x630/?fname=https://t1.daumcdn.net/news/202001/10/yonhap/20200110071011702wnbx.jpg',
'id': 139382726,
'officialCount': 0,
'postKey': '20200110071011691',
'status': 'S',
'title': '스마트홈부터 커넥티드카까지..구글·아마존 AI비서 경쟁 격화',
'type': 'AUTO',
'updatedAt': '2020-01-10T07:11:02+0900',
'url': 'https://news.v.daum.net/v/20200110071011691',
'userId': 0}
로그인 후 데이터 크롤링하기
- endpoint 찾기 (개발자 도구의 network 활용)
- id와 password가 전달되는 form data 찾기
- session 객체 생성하여 login 진행
- endpoint(url)과 data를 구성하여 요청
- login의 경우 post로 구성하는 것이 정상적인 웹사이트이다.
- 이후 session 객체로 원하는 페이지로 이동하여 크롤링
- login 시 사용했던 session을 다시 사용하여 요청
import requests
from bs4 import BeautifulSoup
url = 'Login URL'
data = {
'id': 'Your id'
'pwd': 'Your password'
}
s = requests.Session()
resp = s.post(url, data=data)
url2 = 'Your URL'
resp = s.get(url2)
soup = BeautifulSoup(resp.text)
soup.select('tag')


