Incheon University
2018.09 ~ 2018.12
BRCA 유방암 데이터 분석, 여러 머신러닝 기법을 이용하여 예측 모델 비교분석, DNN/K-means 기법을 이용하여 유방암 예측 모델 개발
Python, Tensorflow, Scikit-learn
https://github.com/hwk0702/BRCA-Breast-Cancer-Prediction-Model-Using-DNN-and-K-means
BRCA Prediction
BRCA Breast Cancer Prediction Model Using DNN and K-means
BRCA Prediction
BRCA Breast Cancer Prediction Model Using DNN and K-means
Incheon University
2018.09 ~ 2018.12
BRCA 유방암 데이터 분석, 여러 머신러닝 기법을 이용하여 예측 모델 비교분석, DNN/K-means 기법을 이용하여 유방암 예측 모델 개발
Python, Tensorflow, Scikit-learn
https://github.com/hwk0702/BRCA-Breast-Cancer-Prediction-Model-Using-DNN-and-K-means
Description
① Execute test data and training data separately.
② Using gene data from patients, distinguishes between good and risky genes.
③ As a result, the program will be makes good and risky predictions of the gene.

i. KNN (k=[3, 5, 7, 9, 11, 13, 15])
ii. Naive Bayesian Classification
iii. Information gain ( max_depth=[3, 5, 7, 9, 11, 13, 15] )
iv. SVM (kernel = [linear, poly, rbf, sigmoid])
v. DNN (solver=[adam, sgd, lbfgs], activation= [identity, logistic, tanh, relu])
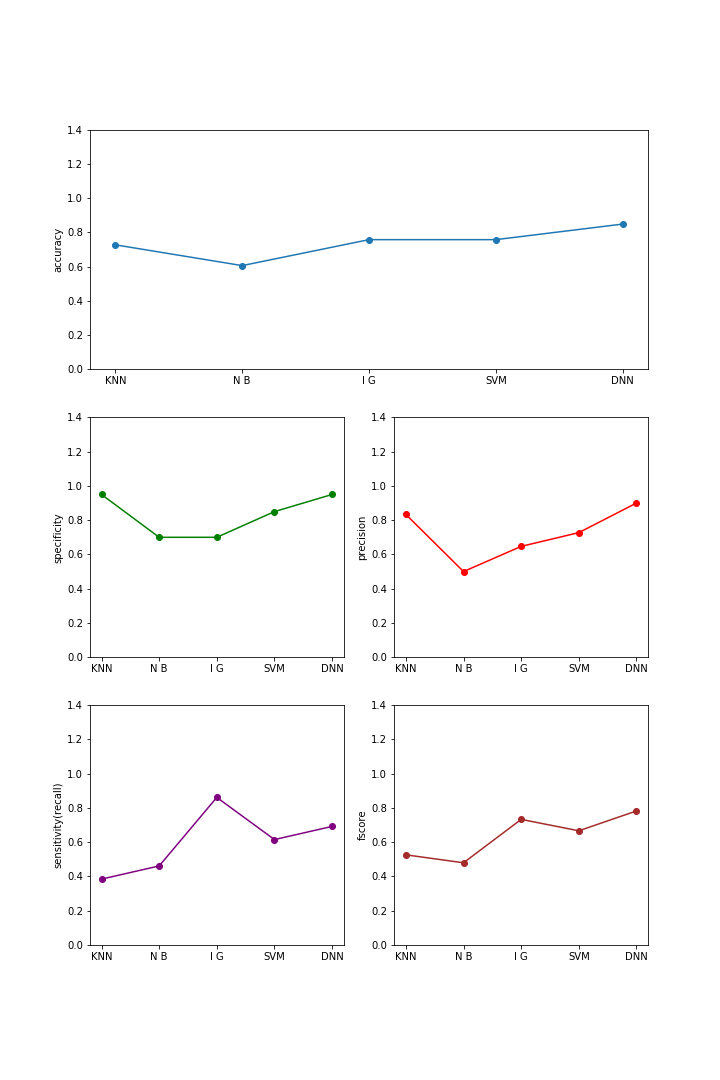
The accuracy of DNN was the highest at about 0.85, and DNN had the highest value except the sensitivity. As a result, DNN (solver = ibfgs, activation = logistic) is the best classification.
When SVM kernel is sigmoid and DNN solver is adman and sgd, it is not classified properly.
1) Preprocessing
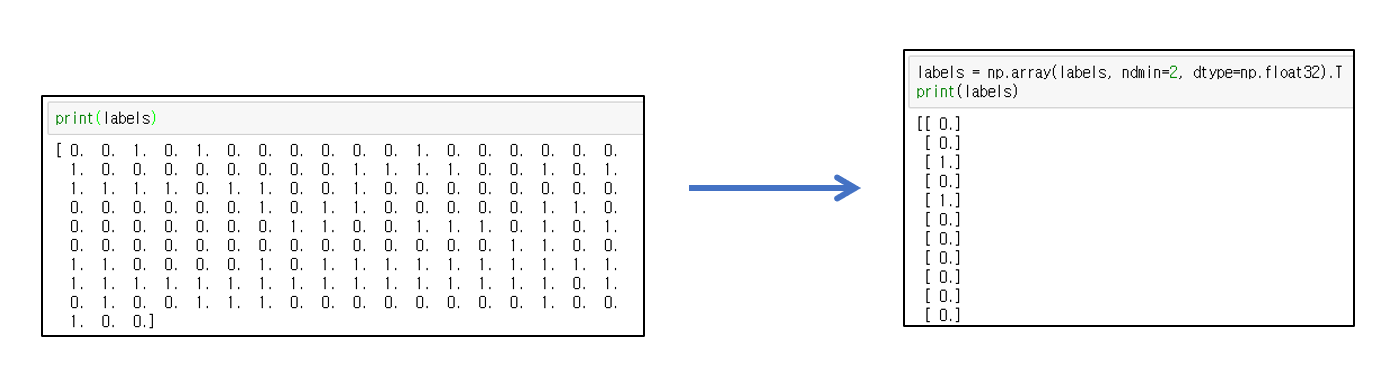
① Edit labels array
For use in the DNN model, the Labels array is changed to a two-dimensional array, and the column vectors are replaced by row vectors.
② One-Hot-Encoding
One-Hot-Encoding is used to change the values of labels. One-Hot-Encoder is also referred to as One-of-K encoding and converts an integer scalar value having a value of 0 to K-1 into a K-dimensional vector having a value of 0 or 1.

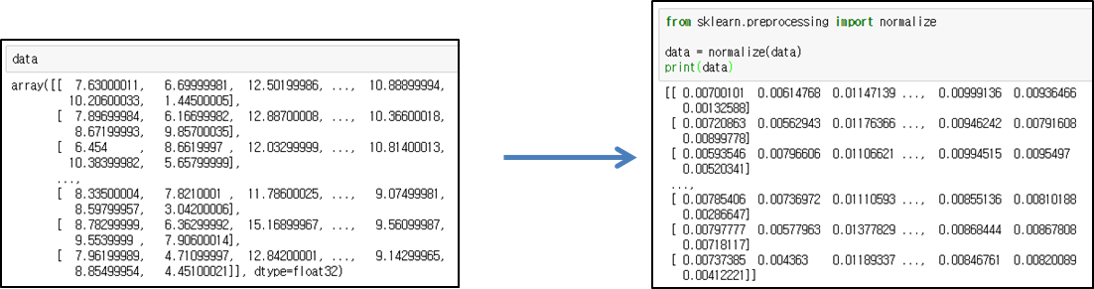
③ Normalization
Normalize the values of the data. Normalization is a transformation to make all of the individual data the same size.
2) Data grouping
Divide into two groups with similar characteristics to get better results.
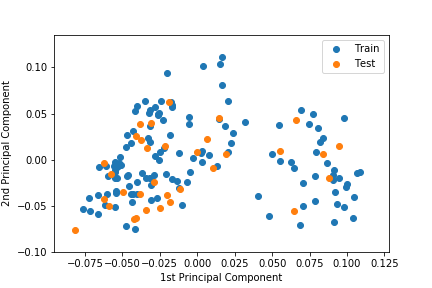
① Principal component analysis (PCA)
The dimension of the data is reduced to two dimensions.
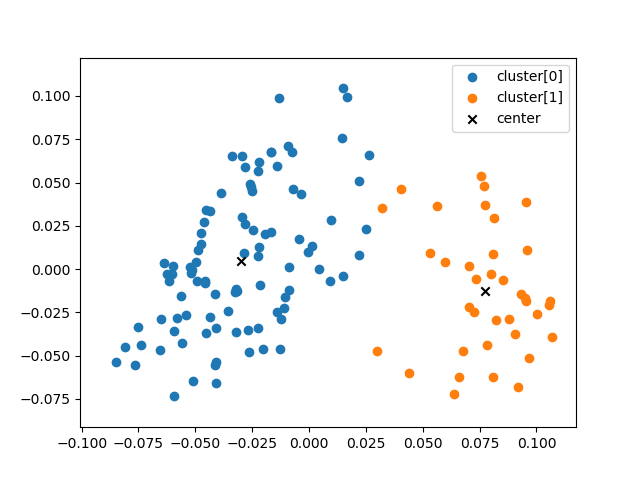
① K-means
Use K-means to divide into two groups.
③ Grouping
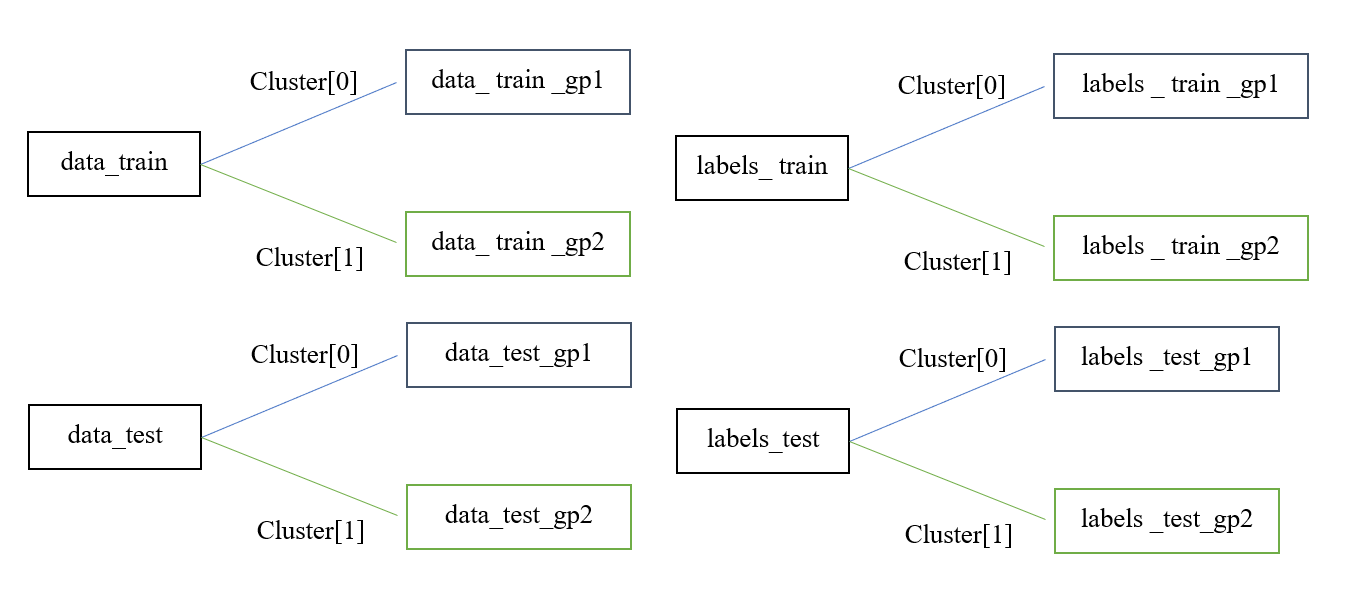
3) Training
① DNN (Deep Neural Network)
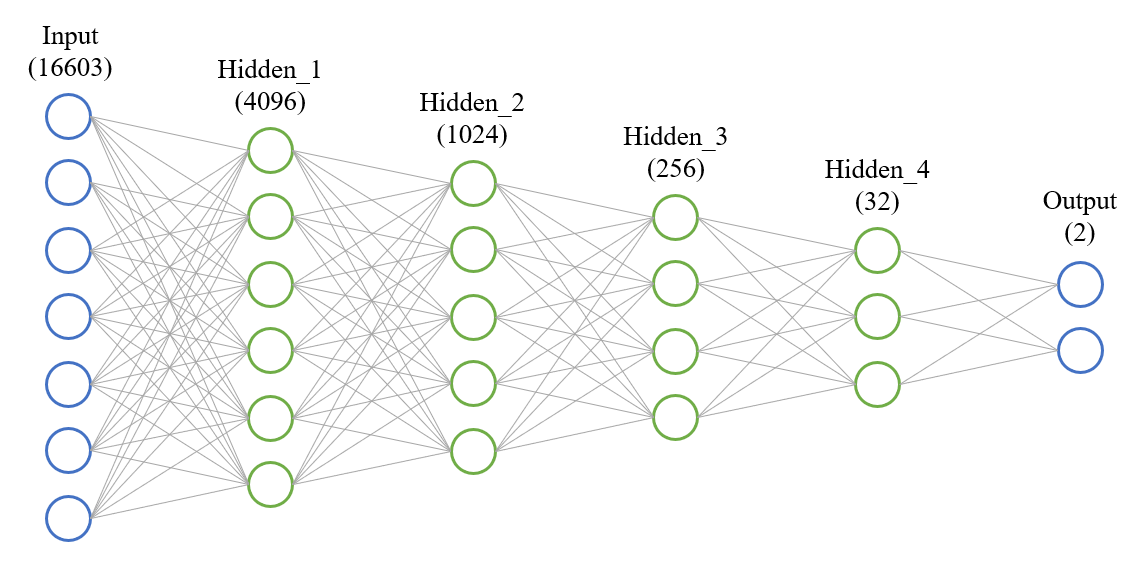
The hidden layer is composed of four layers (4096, 1024, 256, 32) and the Learning_rate is set to 0.0001. I used the solver as the adam optimizer function and the activate function as relu. Train step were set to 500.
② Dropout
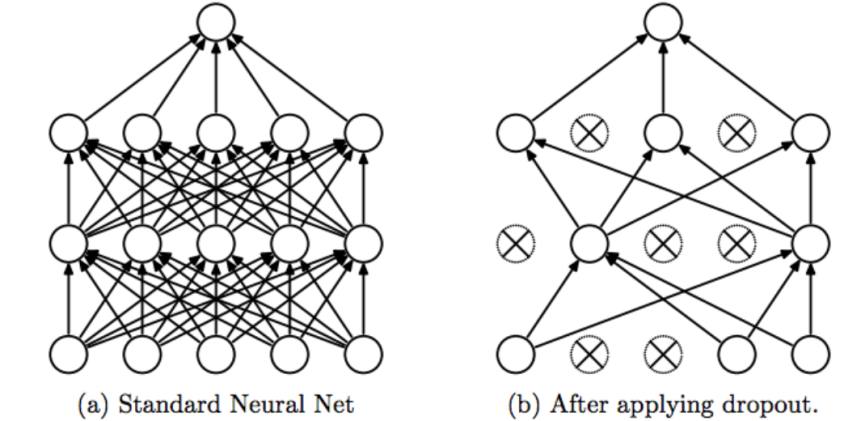
Avoid using some of the neurons at each learning step to prevent some features from sticking to specific neurons, balancing the weights to prevent overfitting.
Dropouts were set to 0.8.
③ Regularization
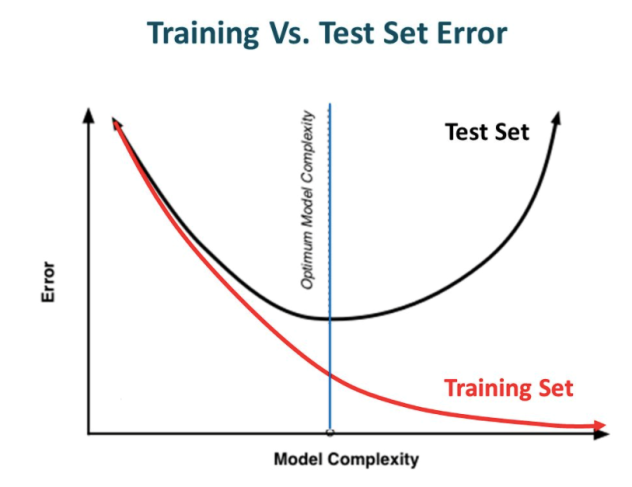
Let’s not have too big numbers in the weight. And, prevent overfitting.
Reularization was set to 0.001.
1) Result
① First Group & Second Group
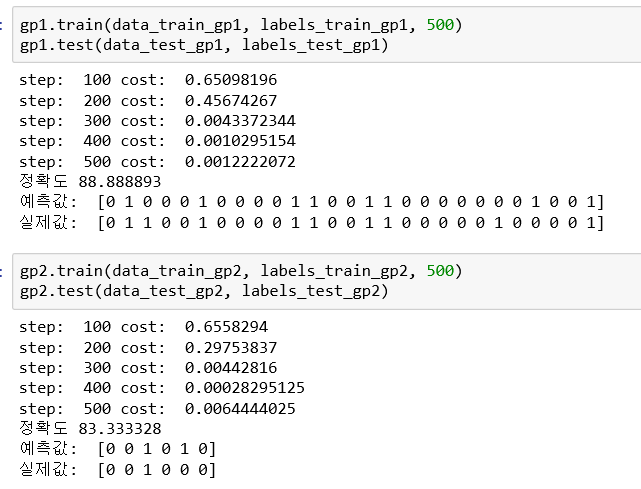
② Sum first group, seconde group result

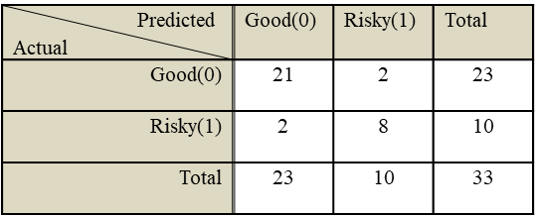

Accuracy was 0.88
2) Compare with other methods
① Not grouping, Not regularization, node(1024,256,32)
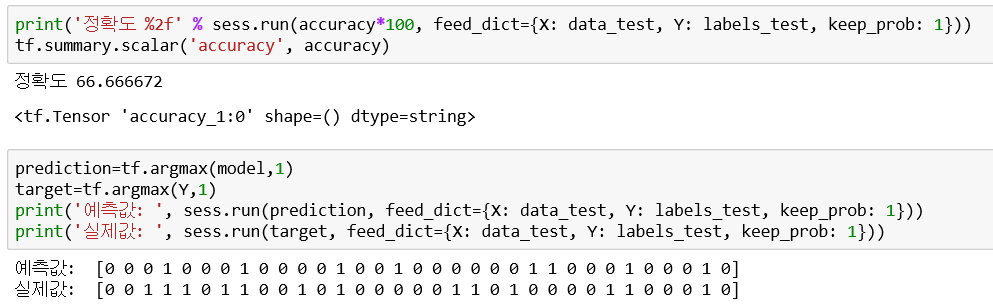
② Not grouping, Not regularization, node(4096,1024,256,32)

③ Not grouping, Use regularization, node(4096,1024,256,32)