Published: Jun 2, 2020 by Dev-hwon
이 내용은 핸즈온 머신러닝 2판 책을 보고 정리한 것 입니다.

앙상블 학습(Ensemble Method)
- 일련의 예측기로부터 예측을 수집하면 가장 좋은 모델 하나보다 더 좋은 예측을 얻을 수 있을 것
- 배깅, 부스팅, 스태킹 등
1. 투표 기반 분류기
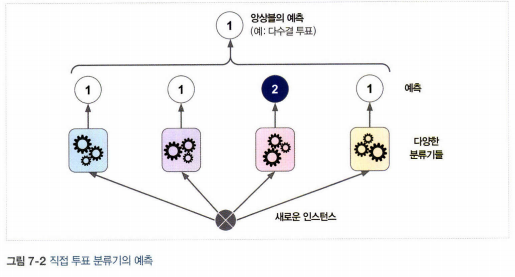
- 직접 투표 분류기: 더 좋은 분류기를 만드는 매우 간단한 방법. 각 분류기의 예측을 모아서 가장 많이 선택된 클래스를 예측. 모든 분류기가 완벽하게 독립적이고 오차에 상관관계가 없어야 가능
- 간접 투표 분류기: 모든 분류기가 클래스의 확률을 예측할 수 있으면 개별 분류기의 예측을 평균 내어 확률이 가장 높은 클래스를 예측. 직접 투표 방식보다 성능이 높다.
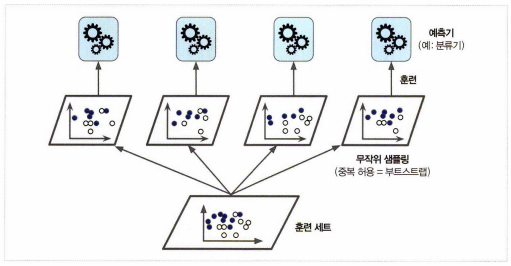
2. 배깅과 페이스팅
- 같은 알고리즘을 사용하고 훈련 세트의 서브셋을 무작위로 구성하여 분류기를 각기 다르게 학습시키는 방법
- 배깅(bagging): 훈련 세트에서 중복을 허용하여 샘플링하는 방식. bootstrap aggregating의 줄임말.
- 페이스팅(pasting): 중복을 허용하지 않고 샘플링 하는 방식
- 분류일 때는 통계적 최빈값, 회귀일 때는 평균을 계산
- 개별 예측기는 원본 훈련 세트로 훈련시킨 것보다 크게 편향. 하지만, 수집 함수를 통과하면 편향과 분산이 모두 감소
- 결과는 하나의 예측기를 훈련시킬 때와 비교해 편향은 비슷하지만 분산이 줄어든다.
- 부트스트래핑은 각 예측기가 학습하는 서브셋에 다양성을 증가시키므로 배깅이 페이스팅보다 편향이 더 높다. 하지만 예측기들의 상관관계를 줄이므로 앙상블의 분산을 감소 (전반적으로 배깅이 페이스팅보다 더 나은 모델을 만듦)
- 예측기는 모두 동시에 다른 CPU 코어나 서버에서 병렬로 학습 가능하여 인기
2.1 oob 평가
- 부트스트랩을 사용할 경 어떤 샘플은 여러번 샘플링되고 어떤 것은 전혀 선택되지 않는 경우가 생김
- 평균적으로 훈련 샘플의 63%가 샘플링되고 나머지 37%는 샘플링 되지 않는다. 이를 .632 bootstrap이라 한다
- 선택되지 않은 37% 샘플을 oob(out-of-bag) 샘플이라고 한다.
- 예측기가 훈련되는 동안 oob 샘플을 사용하지 않으므로 별도의 검증 세트를 사용하지 않고 oob 샘플을 사용해 평가할 수 있다. (각 예측기의 oob 평가를 평균)
3. 랜덤 패치와 랜덤 서브스페이스
- 특성 샘플링: 샘플이 아니고 특성에 대한 샘플링. 각 예측기는 무작위로 선택한 입력 특성의 일부분으로 훈련. max_features, bootstrap_features 두 매개변수로 조절. 고차원 데이터셋을 다룰 때 유용. 편향을 늘리는 대신 분산을 낮춘다.
- 랜덤 패치: 훈련 샘플과 특성 모두 샘플링하는 방식
- 랜덤 서브스페이스: 훈련 샘플은 모두 사용하고 특성은 샘플링하는 방식
4. 랜덤 포레스트
- 배깅 방법(또는 페이스팅)을 적용한 결정 트리 앙상블
- 사이킷런에서 RandomForestClassifier 사용
- 트리의 노드를 분할할 때 전체 특성 중에서 최선의 특성을 찾는 대신 무작위로 선택한 특성 후보 중에서 최적의 특성을 찾는 식
- 편향을 손해보는 대신 분산을 낮추어 더 좋은 모델 생성
- 특성의 상대적 중요도를 측정하기 쉽다.
4.1 엑스트라 트리
- 익스트림 랜덤 트리 앙상블 또는 엑스트라 트리라고 부름
- 트리를 더욱 무작위하게 만들기 위해 최적의 임계값을 찾는 대신 후보 특성을 사용해 무작위로 분할한 다음 그 중에서 최상의 분할을 선택
- 편향이 늘어나지만 분산이 낮아짐
- 최적의 임계값을 찾는 것이 시간이 많이 소요되기 때문에 일반적인 랜덤 포레스트보다 빠르다.
- 사이킷런에서 ExtraTreesRegressor 사용
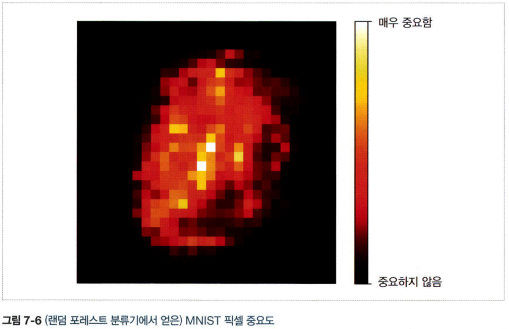
4.2 특성 중요도
- 사이킷런은 어떤 특성을 사용한 노드가 평균적으로 불순도를 얼마나 감소시키는지 확인하여 특성의 중요도를 측정.(가중치 평균, 각 노드의 가중치 = 연관된 훈련 샘플 수)
- 사이킷런은 훈련이 끝난 뒤 특성마다 자동으로 점수 계산. 중요도의 전체 합이 1이 되도록 결괏값을 정규화
- 특성을 선택해야 할 때 어떤 특성이 중요한지 빠르게 확인 가능
5 부스팅
- 약한 학습기를 여러 개 연결하여 강한 학습기를 만드는 앙상블 방법
- 에이다부스트, 그레디언트 부트스트랩을
5.1 에이다부스트
- 이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높이는 것
- 학습하기 어려운 샘플에 점점 더 맞춰지게됨
- 경사 하강법은 비용 함수를 최소화하기 위해 한 예측기의 모델 파라미터를 조정하는 반면 에이다부스트는 앙상블에 예측기를 추가
- 각 예측기는 이전 예측기가 훈련되고 평가된 후에 학습. 따라서 병렬화 불가능
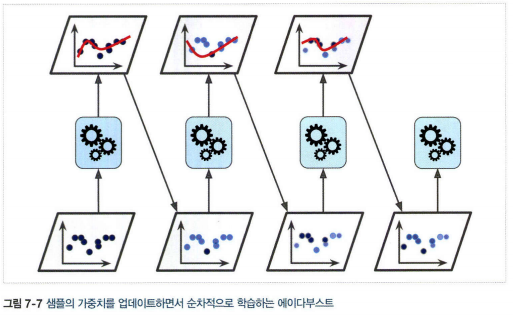
- 배깅이나 페이스팅과 비슷한 방식으로 예측을 만들지만, 가중치가 적용된 훈련 세트의 전반적인 정확도에 따라 예측기마다 다른 가중치가 적용
1) 각 샘플 가중치 \(w^{(i)}\)는 초기에 \(\frac{1}{m}\)로 초기화하고, 예측기가 학습되고 가중치가 적용된 에러율 \(r\)이 훈련 세트에 대해 계산
\(j\)번째 예측기의 가중치가 적용된 에러율
\(r_j=\frac{\underset{\hat{y}_j^{(i)} \neq y^{(i)}}{\sum^m_{i=1}w^{(i)}}}{\sum^m_{i=1}w^{(i)}}\) 여기서 \(\hat{y}_j^{(i)}\)는 \(i\)번째 샘플에 대한 \(j\)번째 예측기의 예측
2) 가중치 \(\alpha_j\)를 계산. \(\eta\)는 학습률 하이퍼파라미터. 예측기가 정확할수록 가중치가 높아진다. 무작위로 예측하는 정도라면 0에 가까워지고 그보다 나쁘면 음수가 된다.
예측기 가중치
\[\alpha_j = \eta log \frac{1-r_j}{r_j}\]3) 샘플의 가중치를 업데이트 한다.
가중치 업데이트 규칙
\[w^{(i)}\leftarrow \left\{\begin{matrix} w^{(i)} & \hat{y_j}^{(i)}=y^{(i)}일 때\\ w^{(i)}exp(\alpha_j) & \hat{y_j}^{(i)} \neq y^{(i)}일 때 \end{matrix}\right.\]4) 모든 샘플의 가중치를 정규화
\[w^{(i)} = \frac{w^{(i)}}{\sum^m_{i=1}w^{(i)}}\]5) 업데이트된 가중치 사용 훈련 및 반복.(지정된 예측기 수에 도달하거나 완벽한 예측기가 만들어지면 중지)
6) 예측을 할 때 모든 예측기의 예측을 계산하고 예측기 가중치 \(\alpha_j\)를 더해 예측 결과 만들고, 가중치 합이 가장 큰 클래스가 예측 결과가 된다
\(\hat{y}(\mathbf{x})=\underset{x}{argmax}\underset{\hat{y}_j(\mathbf{x})=k}{\sum^N_{j=1}}\alpha_j\) 여기서 \(N\)은 예측기 수
5.2 그레디언트 부스팅
- 에이다부스트처럼 반복마다 샘플의 가중치를 수정하는 대신 이전 예측기가 만든 잔여 오차에 새로운 예측기를 학습
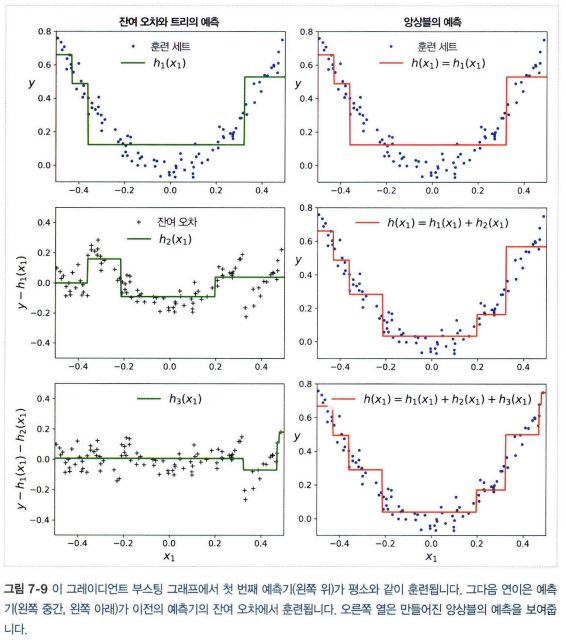
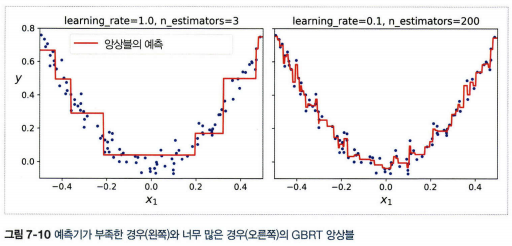
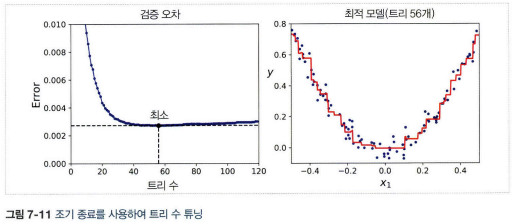
- 확률적 그레디언트 부스팅: 훈련할 때 사용할 훈련 샘플의 비율을 지정하는 방식. 편향이 높아지는 대신 분산이 낮아지고 훈련 속도가 빨라진다.
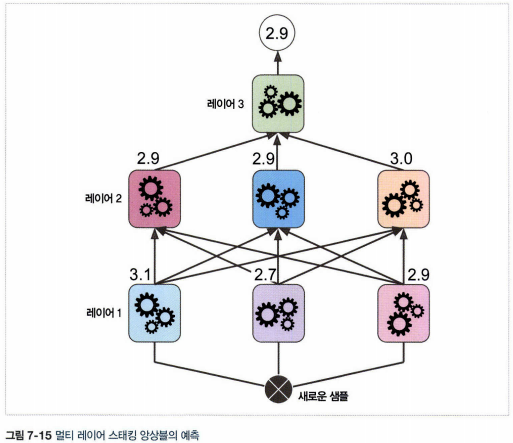
6. 스태킹
- 앙상블에 속한 모든 예측기의 예측을 취합하는 마지막 예측기(블렌더 또는 메타 학습기)를 만들어 최종 예측을 만드는 방법
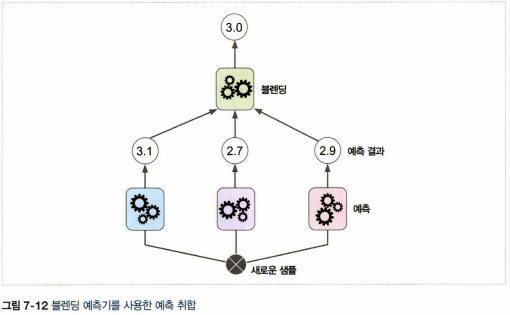
- 홀드 아웃 세트를 사용
1) 훈련 세트를 두 개의 서브셋으로 나눈다.
2) 첫 번째 서브셋은 첫번째 레이어의 예측을 훈련시키기 위해 사용한다.
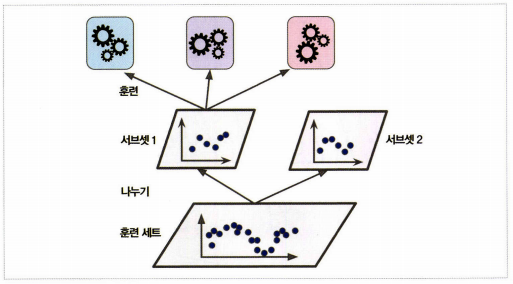
3) 첫 번째 레이어의 예측기를 사용해 두 번째(홀드 아웃) 세트에 대한 예측을 만든다
4) 홀드 아웃 세트의 각 샘플에 대한 예측값들과 타깃 값을 이용하여 새로운 훈련 세트를 만든다
5) 블렌더를 새 훈련 세트로 훈련한다.
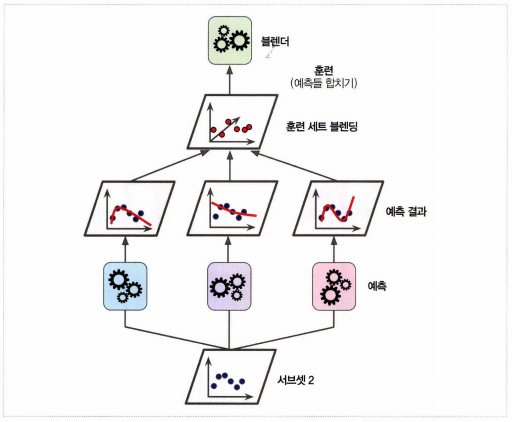
- 블렌더를 여러 개 훈련시키는 것도 가능하다.