Published: Jan 17, 2020 by Dev-hwon
이 내용은 케라스 창시자에게 배우는 딥러닝 책을 보고 정리한 것 입니다.
.jpg)
순환 신경망 (Recurrent Neural Network, RNN)
- 시퀀스의 원소를 순회하면서 지금까지 처리한 정보를 상태(state)에 저장
- 내부에 루프(loop)를 가진 신경망의 한 종류
- 하나의 시퀀스가 하나의 데이터 포인트
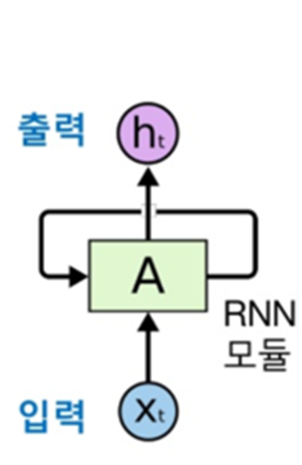
- 시퀀스는 타임스텝을 따라서 반복
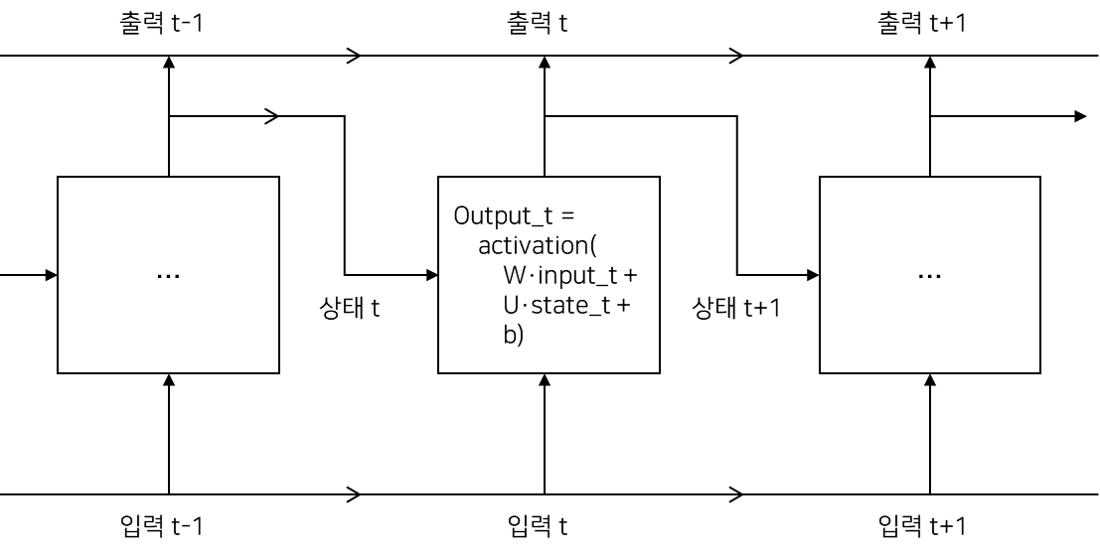
- 각 타임스텝 t에서 현재 상태와 ((input_features,) 크기의) 입력을 연결하여 출력을 계산
- 그다음 이 출력을 다음 스텝의 상태로 설정 (초기 상태는 0인 벡터)
SimpleRNN
-
두 가지 모드
- 전체 시퀀스 반환 (크기가 (batch_size, timestaps, output_features)인 3D 텐서)
- 마지막 출력만 반환 (크기가 (batch_size, output_features)인 2D 텐서)
-
예제
# 마지막 타임스텝의 출력만 반환
from keras.models import Sequential
from keras.layers import SimpleRNN
model = Sequential()
model.add(SimpleRNN(32))
# 전체 시퀀스 반환
from keras.models import Sequential
from keras.layers import SimpleRNN
model = Sequential()
model.add(SimpleRNN(32, return_sequences=True))
# SimpleRNN 층을 사용한 모델 훈련
from keras.models import Sequential
from keras.layers import Dense, SimpleRNN
model = Sequential()
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.complie(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
- SimpleRNN은 이론적으로 시간 t에서 이전의 모든 타임스텝의 정보를 유지할 수 있다. 하지만, 실제로는 긴 시간에 걸친 의존성은 학습할 수 없는 것이 문제
- 그래디언트 소실 문제: 역전파가 진행되는 동안 타임스텝마다 동일한 가중치를 사용하기 때문에 타임스텝이 길어질수록 그래디언트 값이 급격히 줄어들거나 급격히 증가하는 문제
LSTM (Long Short-Term Memory)
- 1997년 호크라이터와 슈미트후버가 개발
- 정보를 여러 타임스텝에 걸쳐 나르는 방법이 추가
- 오래된 시그널이 점차 소실되는 것을 방지

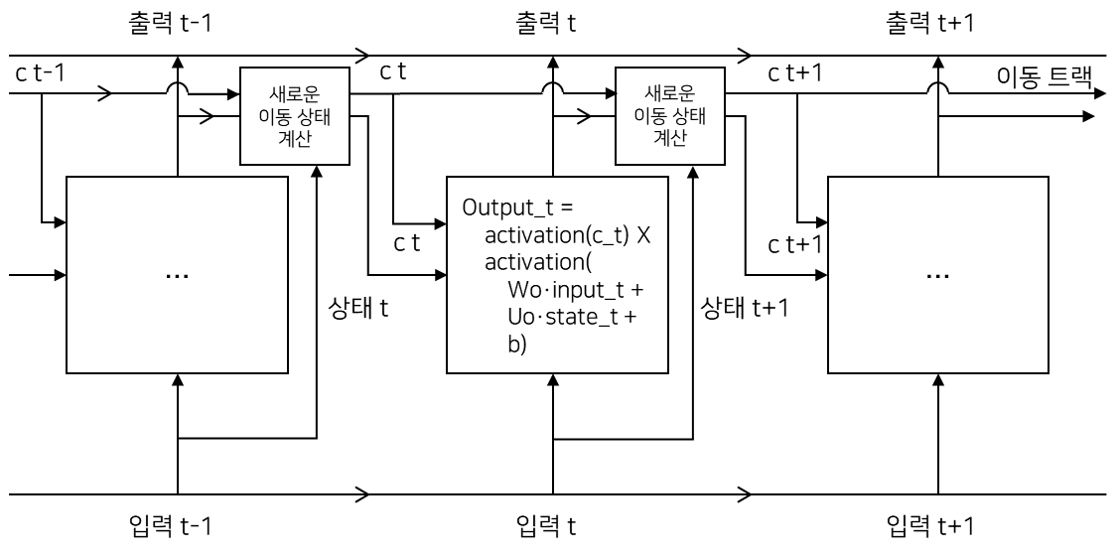
정보를 나르는 데이터 흐름 추가. 입력 연결과 순환 연결(상태)로부터 정보 합성(가중치 행렬과 점곱한 후 편향을 더하고 활성화 함수 적용). 다음 타임스텝으로 전달될 상태를 변경
- 다음 이동 상태(c_t+1)가 계산되는 방법
3개의 변환(모두 SimpleRNN과 같은 형태)이 존재하고, 자신만의 가중치 행렬을 가짐.
output_t = activation(c_t) * activation(dot(input_t, Wo) + dot(state_t, Uo) + b0)
i_t = activation(dot(state_t, Ui) + dot(input_t, Wi) + bi)
f_t = activation(dot(state_t, Uf) + dot(input_t, Wf) + bf)
k_t = activation(dot(state_t, Uk) + dot(input_t, Wk) + bk)
c_t + 1 = i_t * k_t + c_t * f_t
c_t * f_t : 데이터 흐름에서 관련이 적은 정보를 삭제 i_t, k_t : 현재에 대한 정보를 제공, 이동 트랙을 새로운 정보로 업데이트
하지만 연산들이 실제로 하는 일은 연산에 관련된 가중치 행렬에 따라 결정 가중치는 end-to-end 방식으로 학습
- 예제
from keras.models import Sequential
from keras.layer import LSTM, Dense
model = Sequential()
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.complie(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
고급 사용법
- 순환 드롭아웃(Recurrent dropout): 순환 층에서 과대적합을 방지하기 위해 내장되어 있는 드롭아웃 사용
- 스태킹 순환 층(Stacking recurrent layer): 네트워크의 표현 능력을 증가(계산 비용 증가)
- 양방향 순환 층(Bidirecional recurren layer): 순환 네트워크에 같은 정보를 다른 방향으로 주입하여 정확도를 높이고 더 오래 기억하게 유지


